TensorFlowLite-Micro(TFLM))
支持的芯片
芯片 |
RTL8721Dx |
RTL8720E |
RTL8713E |
RTL8726E |
RTL8730E |
|---|---|---|---|---|---|
支持内核 |
KM4 |
KM4 |
KM4,DSP |
KM4,DSP |
CA32 |
概述
TensorFlowLite-Micro(TFLM)是一个开源库,它是 TensorFlow Lite 的一个移植版本,专为数字信号处理器(DSP)、微控制器和其他内存有限的设备而设计,以便在这些设备上运行机器学习模型。
Ameba-tflite-micro 是针对 Realtek Ameba 系列芯片的 TFLM 库的优化版本,包含平台相关的优化,可以在 ameba-rtos SDK 中获取。
编译 TFLM
在 SDK 的 menuconfig 中打开 tflite_micro 配置来编译 TFLM 库。
切换到 SDK 的 GCC 项目目录
cd {SDK}/amebadplus_gcc_project
运行
menuconfig.py进入配置界面./menuconfig.py
导航至以下菜单路径开启 TFLM 配置
----MENUCONFIG FOR General---- CONFIG TrustZone ---> ... CONFIG APPLICATION ---> GUI Config ---> ... AI Config ---> [*] Enable TFLITE MICRO
以
tflm_hello_world为例,执行以下命令编译固件:./build.py -a tflm_hello_world
更多 TFLM 相关示例位于
{SDK}/component/example/tflite_micro目录下。
KM4
在 SDK 的 menuconfig 中打开 tflite_micro 配置来编译 KM4 核 上的 TFLM 库。
切换到 SDK 的 GCC 项目目录
cd {SDK}/amebalite_gcc_project
运行
menuconfig.py进入配置界面./menuconfig.py
导航至以下菜单路径开启 TFLM 配置
----MENUCONFIG FOR General---- CONFIG TrustZone ---> ... CONFIG APPLICATION ---> GUI Config ---> ... AI Config ---> [*] Enable TFLITE MICRO
以
tflm_hello_world为例,执行以下命令编译固件:./build.py -a tflm_hello_world
更多 TFLM 相关示例位于
{SDK}/component/example/tflite_micro目录下。
DSP
在 Xtensa Xplorer 中把 {DSPSDK}/lib/tflite_micro 作为项目导入工作区来编译 DSP 上的 TFLM 库。
点击 ,选择
{DSPSDK}/lib/tflite_micro的路径。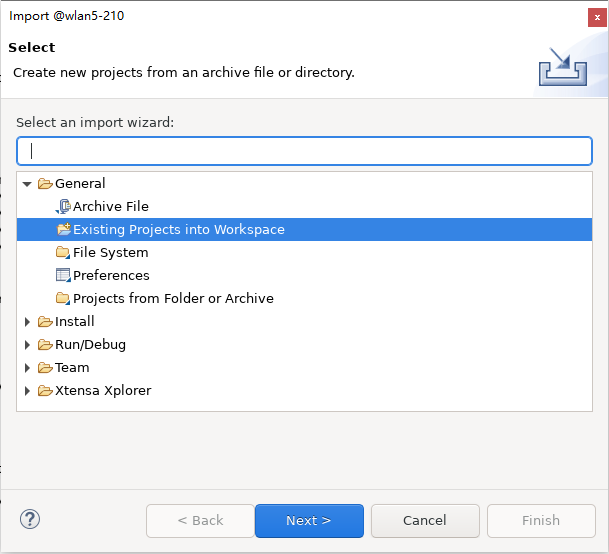
设置 P 为
libtflite_micro,C 为HIFI5_PROD_1123_asic_UPG或HIFI5_PROD_1123_asic_wUPG, T 为Release,然后点击Build Active。输出的库会保存在
{DSPSDK}/lib/tflite_micro/project/bin/HIFI5_PROD_1123_asic_UPG/Release目录下。
编译示例固件的步骤请参考 DSP 编译,软件相关配置请参考示例目录下的 README 文件。
TFLM 相关示例位于
{DSPSDK}/example/tflite_micro目录下。
KM4
在 SDK 的 menuconfig 中打开 tflite_micro 配置来编译 KM4 核 上的 TFLM 库。
切换到 SDK 的 GCC 项目目录
cd {SDK}/amebalite_gcc_project
运行
menuconfig.py进入配置界面./menuconfig.py
导航至以下菜单路径开启 TFLM 配置
----MENUCONFIG FOR General---- CONFIG TrustZone ---> ... CONFIG APPLICATION ---> GUI Config ---> ... AI Config ---> [*] Enable TFLITE MICRO
以
tflm_hello_world为例,执行以下命令编译固件:./build.py -a tflm_hello_world
更多 TFLM 相关示例位于
{SDK}/component/example/tflite_micro目录下。
DSP
在 Xtensa Xplorer 中把 {DSPSDK}/lib/tflite_micro 作为项目导入工作区来编译 DSP 上的 TFLM 库。
点击 ,选择
{DSPSDK}/lib/tflite_micro的路径。
设置 P 为
libtflite_micro,C 为HIFI5_PROD_1123_asic_UPG或HIFI5_PROD_1123_asic_wUPG, T 为Release,然后点击Build Active。输出的库会保存在
{DSPSDK}/lib/tflite_micro/project/bin/HIFI5_PROD_1123_asic_UPG/Release目录下。
编译示例固件的步骤请参考 DSP 编译,软件相关配置请参考示例目录下的 README 文件。
TFLM 相关示例位于
{DSPSDK}/example/tflite_micro目录下。
KM4
在 SDK 的 menuconfig 中打开 tflite_micro 配置来编译 KM4 核 上的 TFLM 库。
切换到 SDK 的 GCC 项目目录
cd {SDK}/amebalite_gcc_project
运行
menuconfig.py进入配置界面./menuconfig.py
导航至以下菜单路径开启 TFLM 配置
----MENUCONFIG FOR General---- CONFIG TrustZone ---> ... CONFIG APPLICATION ---> GUI Config ---> ... AI Config ---> [*] Enable TFLITE MICRO
以
tflm_hello_world为例,执行以下命令编译固件:./build.py -a tflm_hello_world
更多 TFLM 相关示例位于
{SDK}/component/example/tflite_micro目录下。
在 SDK 的 menuconfig 中打开 tflite_micro 配置来编译 TFLM 库。
切换到 SDK 的 GCC 项目目录
cd {SDK}/amebasmart_gcc_project
运行
menuconfig.py进入配置界面./menuconfig.py
导航至以下菜单路径开启 TFLM 配置
----MENUCONFIG FOR General---- CONFIG TrustZone ---> ... CONFIG APPLICATION ---> GUI Config ---> ... AI Config ---> [*] Enable TFLITE MICRO
以
tflm_hello_world为例,执行以下命令编译固件:./build.py -a tflm_hello_world
更多 TFLM 相关示例位于
{SDK}/component/example/tflite_micro目录下。
示例教程
MNIST 简介
MNIST (Modified National Institute of Standards and Technology database) 是一个大型手写体数字的图片数据集,广泛用于机器学习模型的训练和验证。
本教程基于 MNIST 数据集,展示 从训练模型到部署,并在 Ameba SoC 上使用 TFLM 进行 推理 的完整流程。
示例代码: {SDK}/component/example/tflite_micro/tflm_mnist。
实验步骤
备注
步骤 1-4 是为了在开发机器(服务器或个人电脑等)上准备必要的文件。您也可以跳过这些步骤,直接使用 SDK 中准备好的文件来编译固件。
步骤 1:训练模型
使用 Keras(TensorFlow)或 PyTorch 训练 MNIST 10 个数字的分类模型。
示例所用模型是一个以卷积为主的简单网络结构,在数据集上进行几轮训练迭代后,测试它的准确率。
运行脚本
python keras_train_eval.py --output keras_mnist_conv
训练完成后,Keras 模型以 SavedModel 格式保存在 keras_mnist_conv 目录下。
备注
由于微处理器的 算力 和 内存 有限,建议关注 模型大小 以及 运算操作数。在 keras_train_eval.py 脚本中,使用了 keras_flops 库:
from keras_flops import get_flops
model.summary()
flops = get_flops(model, batch_size=1)
运行脚本
python torch_train_eval.py --output torch_mnist_conv
训练完成后,PyTorch 模型以 .pt 格式保存,同时还会导出一个 .onnx 文件,用于后续的转换。
备注
由于微处理器的 算力 和 内存 有限,建议关注 模型大小 以及 运算操作数。在 torch_train_eval.py 脚本中,使用了 ptflops 库:
from ptflops import get_model_complexity_info
macs, params = get_model_complexity_info(model, (1,28,28), as_strings=False)
步骤 2:转换成 Tflite 文件
对训练好的模型应用 训练后整数量化,输出为 .tflite 格式文件。
Ameba SoC 也支持浮点模型的推理,但仍建议使用整数量化,因为它可以在性能下降很小的情况下,极大地减少计算量和内存。
有关全整数量化的更多详细信息,请参考 tflite 官网 。
运行脚本
python convert.py --input-path keras_mnist_conv/saved_model --output-path keras_mnist_conv
备注
convert.py 脚本细节说明:
使用 tf.lite.TFLiteConverter 转换 SavedModel 为 .tflite 格式
通过以下设置实现 int8 量化:
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = repr_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 converter.inference_output_type = tf.int8 tflite_int8_model = converter.convert()
运行脚本
python convert.py --input-path torch_mnist_conv/model.onnx --output-path torch_mnist_conv
备注
convert.py 脚本细节说明:
使用 onnx-tensorflow 库 转换 .onnx 为 SavedModel 格式
使用 tf.lite.TFLiteConverter 转换 SavedModel 为 .tflite 格式
通过以下设置实现 int8 量化:
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = repr_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 converter.inference_output_type = tf.int8 tflite_int8_model = converter.convert()
转换完成后,示例将使用 int8 .tflite 模型验证测试集性能,并生成两个包含了 100 张测试图像的输入和标签数组的 .npy 文件,以供稍后在 Ameba SoC 上使用。
步骤 3:优化 Tflite 并转换成 C++
运行 tflite-micro 官方目录提供的 tflm_model_transforms 工具:
git clone https://github.com/tensorflow/tflite-micro.git cd tflite-micro bazel build tensorflow/lite/micro/tools:tflm_model_transforms bazel-bin/tensorflow/lite/micro/tools/tflm_model_transforms --input_model_path=</path/to/my_model.tflite> # 输出文件位于: /path/to/my_model_tflm_optimized.tflite
备注
该工具通过一些 TFLM 特定的转换来减小 .tflite 文件的大小。它还通过 C++ flatbuffer API 重新对齐了 tflite flatbuffer,可以在某些 Ameba SoC 上加快推理速度。
此步骤是可选的,但强烈建议执行这步操作。
运行以下命令,把 .tflite 模型和 .npy 测试数据转换成部署所需的 .cc 和 .h 格式文件:
python generate_cc_arrays.py models int8_tflm_optimized.tflite python generate_cc_arrays.py testdata input_int8.npy input_int8.npy label_int8.npy label_int8.npy
步骤 4:在芯片上用 TFLM 推理
example_tflm_mnist.cc 展示了如何使用训练好的模型在测试数据上运行推理,计算准确率,并且统计内存和延迟情况。
使用 netron 来可视化 .tflite 文件并查看模型使用的算子,然后实例化操作解析器来注册和使用所需算子。
using MnistOpResolver = tflite::MicroMutableOpResolver<4>;
TfLiteStatus RegisterOps(MnistOpResolver& op_resolver) {
TF_LITE_ENSURE_STATUS(op_resolver.AddFullyConnected());
TF_LITE_ENSURE_STATUS(op_resolver.AddConv2D());
TF_LITE_ENSURE_STATUS(op_resolver.AddMaxPool2D());
TF_LITE_ENSURE_STATUS(op_resolver.AddReshape());
return kTfLiteOk;
}
有关使用 TFLM 进行推理的更多详细信息,请参考 tflite-micro 官方网站 。
步骤 5:编译
按照 编译 TFLM 中的步骤编译固件。